5 Most Used Types of Machine Learning
Machine learning (ML) is a type of artificial intelligence that enables systems to learn from data and improve over time. There are many different types of machine learning, each with its own strengths and applications. In this blog post, we will explore 5 types of machine learning. We will discuss what these methods are used for and provide list of their algorithms. By understanding the various types of machine learning, you will be better equipped to choose the right approach for your data needs.
What is machine learning
Machine learning is a subset of artificial intelligence that focuses on giving computers the ability to learn and improve from experience without being explicitly programmed to do so. In other words, machine learning is a way of teaching computers to do things that they haven’t been specifically programmed to do. This might sound like a strange concept, but it’s actually something that we see all around us. For example, when you search for something on Google, the results that you see are based on what other people have searched for in the past. Google uses machine learning to analyse this data and give you the most relevant results. Another example of machine learning is when you use your credit card at a store. The credit card company is using machine learning to detect fraudulent activity by analysing patterns in past transactions. Robots in the cognitive robotics field also rely on machine learning in order to improve their understanding of their surroundings over time. This allows them to adapt to new situations and learn from past experiences.
Top 5 Types of Machine Learning
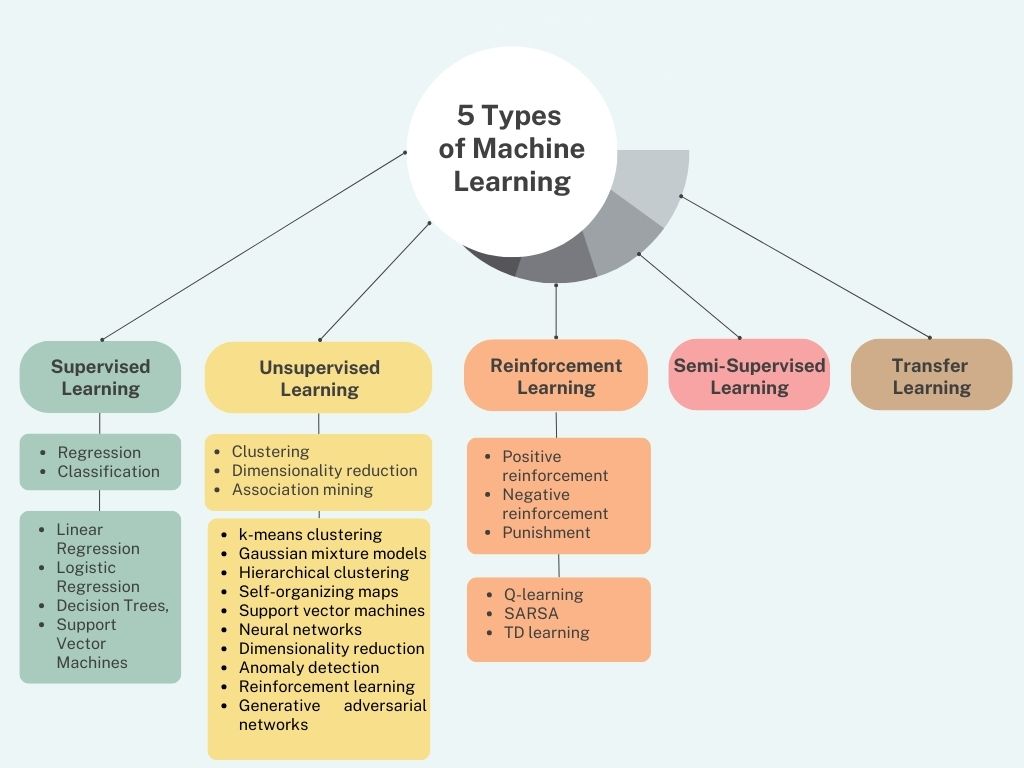
1. Supervised Learning
Supervised Learning is a type of machine learning where the algorithm is “trained” on a set of data that is labelled with the correct answers. The goal is to then take this trained algorithm and apply it to new, unlabelled data in order to make predictions. For example, a supervised learning algorithm could be used to automatically label images of animals as “cat” or “dog”. The training data would need to be a set of labeled images (e.g., an image that has been manually labelled as a “cat”), and the goal would be for the algorithm to learn from this training data so that it can accurately label new, unlabelled images. Supervised learning is one of the most popular types of machine learning, and there are many different algorithms that can be used for supervised learning tasks.
types of supervised learning
There are two main types of supervised learning: regression and classification.
- In regression, the goal is to learn a continuous function that can be used to predict a real-valued output for any new input.
- In classification, the goal is to learn a discrete function that can be used to assign each new input to one of a set of predetermined classes.
Supervised machine learning algorithms
Some of the most popular supervised learning algorithms include:
- Linear Regression
- Logistic Regression
- Decision Trees
- Support Vector Machines
More about supervised learning algorithms on machine learning algorithms post.
2. Unsupervised Learning
Unsupervised learning is a type of machine learning that can be used to find patterns in data. Unlike supervised learning, which requires labelled data, unsupervised learning can be used with data that is not labeled. This makes it helpful for finding hidden patterns or groups in data. For example, unsupervised learning could be used to cluster data points into different groups. This would be useful for finding out whether there are any subgroups within a dataset. Additionally, unsupervised learning can be used for dimension reduction. This means that it can help to reduce the amount of data that needs to be processed by a machine learning algorithm. As a result, unsupervised learning can be helpful for making machine learning more efficient.
Types of unsupervised learning
There are many different types of unsupervised learning, but some of the most commonly used are Clustering, dimensionality reduction, and association mining.
- Clustering: In clustering data is grouped together based on similarity. This can be done in a number of ways, but the most common approach is to use algorithms that group data points together that are close together in terms of some distance metric (e.g. Euclidean distance). Clustering is often used to group data points that are not linearly separable, and as such it can be seen as a way of finding structure in data. Clustering algorithms are also often used as a pre-processing step for other machine learning tasks such as classification and regression.
- Dimensionality Reduction: It is the process of reducing the number of features in a data set. This can be done for a variety of reasons, including simplifying the data set, reducing the storage requirements, or increasing the computational efficiency. There are two main types of dimensionality reduction: supervised and unsupervised. Supervised methods involve training a model on a labelled data set, while unsupervised methods do not require labels. One common unsupervised method is principal component analysis (PCA), which finds the directions that maximize the variance in the data. Dimensionality reduction can be an effective way to improve the performance of machine learning algorithms, and it is an important tool in data science.
- Association mining: Association rules are typically represented as if-then statements, where the if part represents a condition and the then part represents the outcome. For example, an association rule might state that if a customer buys a product A, then they are also likely to buy product B. Association rules can be used to predict future events or to make recommendations. For example, if a customer buys product A, the system might recommend product B. Association rule learning is a powerful tool for making sense of large datasets and can be used for a variety of applications.
Unsupervised learning algorithms
There are a variety of unsupervised machine learning algorithms available, each with its own advantages and disadvantages. Some of the most well-known algorithms include:
- k-means clustering
- Gaussian mixture models
- Hierarchical clustering
- Self-organizing maps
- Support vector machines
- Neural networks
- Dimensionality reduction
- Anomaly detection
- Generative adversarial networks
More about unsupervised learning algorithms on machine learning algorithms post.
3. Reinforcement Learning
Reinforcement learning is a machine learning type where an agent learned by interacting with its environment to obtain the optimal behaviour within that environment. The agent explored the environment and tried different actions to get rewards. Based on these trials, the agent updated its understanding of the environment and what actions work best so it can repeat successful behaviours and avoid unsuccessful behaviour.
The goal of reinforcement learning is to maximize long-term rewards, not immediate rewards like some other machine learning methods such as supervised learning.
An important distinction of reinforcement learning compared to supervised learning is that in reinforcement learning, an agent learns from scratch without being provided with labelled data like in supervised learning. Another key difference is that in reinforcement learning, an agent has to discover which actions yield the greatest rewards by trying them out rather than being told what the correct actions are. There are many different types of reinforcement learning algorithms, but they all aim to help an agent learn how to optimize its behaviour to get the best long-term rewards.
Types of reinforcement learning
There are three main types of reinforcement learning: positive reinforcement, negative reinforcement, and punishment.
- Positive reinforcement occurs when a behaviour is rewarded in order to increase the likelihood of that behaviour being repeated.
- Negative reinforcement occurs when a behaviour is rewarded in order to decrease the likelihood of that behaviour being repeated.
- Punishment occurs when a behaviour is punished in order to decrease the likelihood of that behaviour being repeated.
Reinforcement Learning algorithms
The most popular Reinforcement Learning algorithms:
- Q-learning
- SARSA
- TD learning
These algorithms are used to solve problems such as finding the shortest path between two points or learning how to play a game such as chess. More about reinforcement Learning algorithms on machine learning algorithms post.
4. Semi-Supervised Learning
Semi-supervised learning is a machine learning technique that falls between supervised and unsupervised learning. While supervised learning requires a dataset that is labeled with the correct answers, unsupervised learning doesn’t require any such labels. Semi-supervised learning algorithms make use of both labeled and unlabeled data to learn from. This approach can be used when there is a lot of data available but only a limited amount of it is labeled. It can also be used when the labeling process is expensive or time-consuming. Semi-supervised learning algorithms have been shown to be effective at tasks such as image classification and speech recognition. They are typically more accurate than purely unsupervised methods and can be trained faster than purely supervised methods.
5. Transfer Learning
In machine learning, transfer learning is a technique that can be used to improve the performance of a machine learning model by using knowledge that has been learned in one context and applying it to another context. For example, if a model has been trained on data from a similar but different dataset, then the model can be transferred to the new dataset and fine-tuned to improve its performance. Transfer learning is often used when there is insufficient data available to train a model from scratch. It can also be used to avoid overfitting, which is when a model memorizes the training data too closely and does not generalize well to new data. When used correctly, transfer learning can be an effective way to improve the performance of machine learning models.